Machine Learning Engineer and Incoming HCI PhD Student
Portfolio
Collins Aerospace
Machine Learning Meets Aerospace
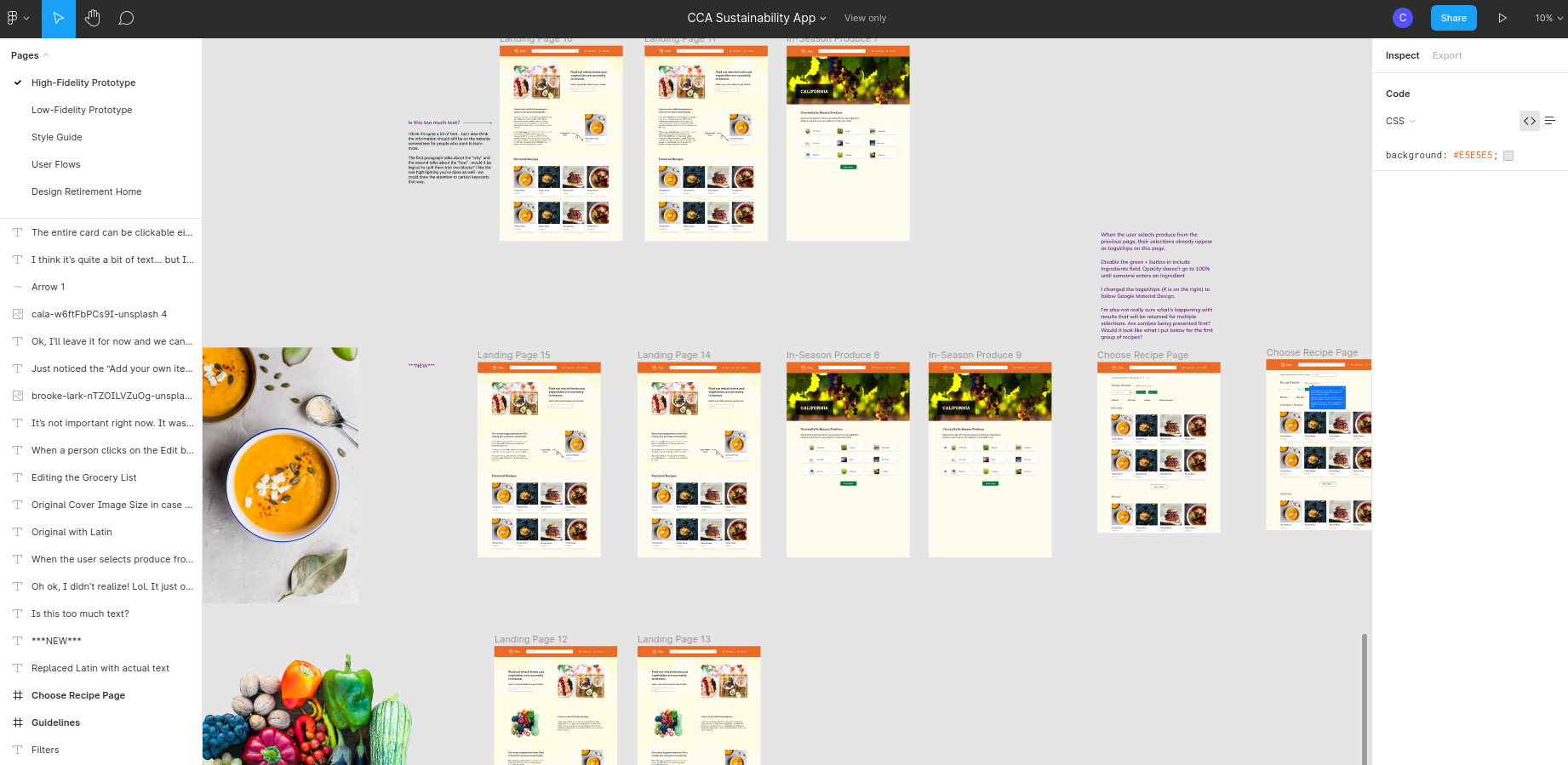
Rekku
Anime Recommendation System
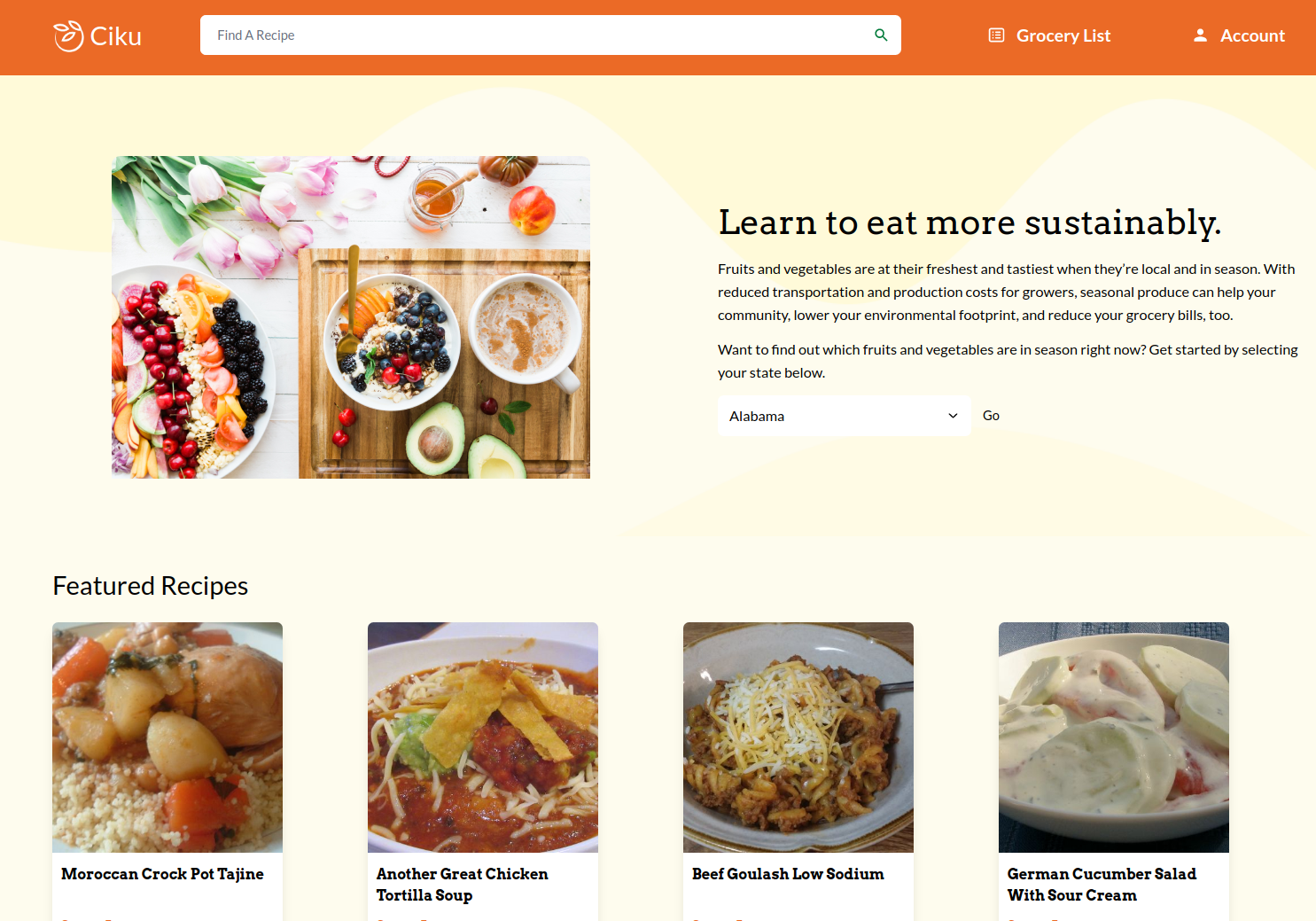
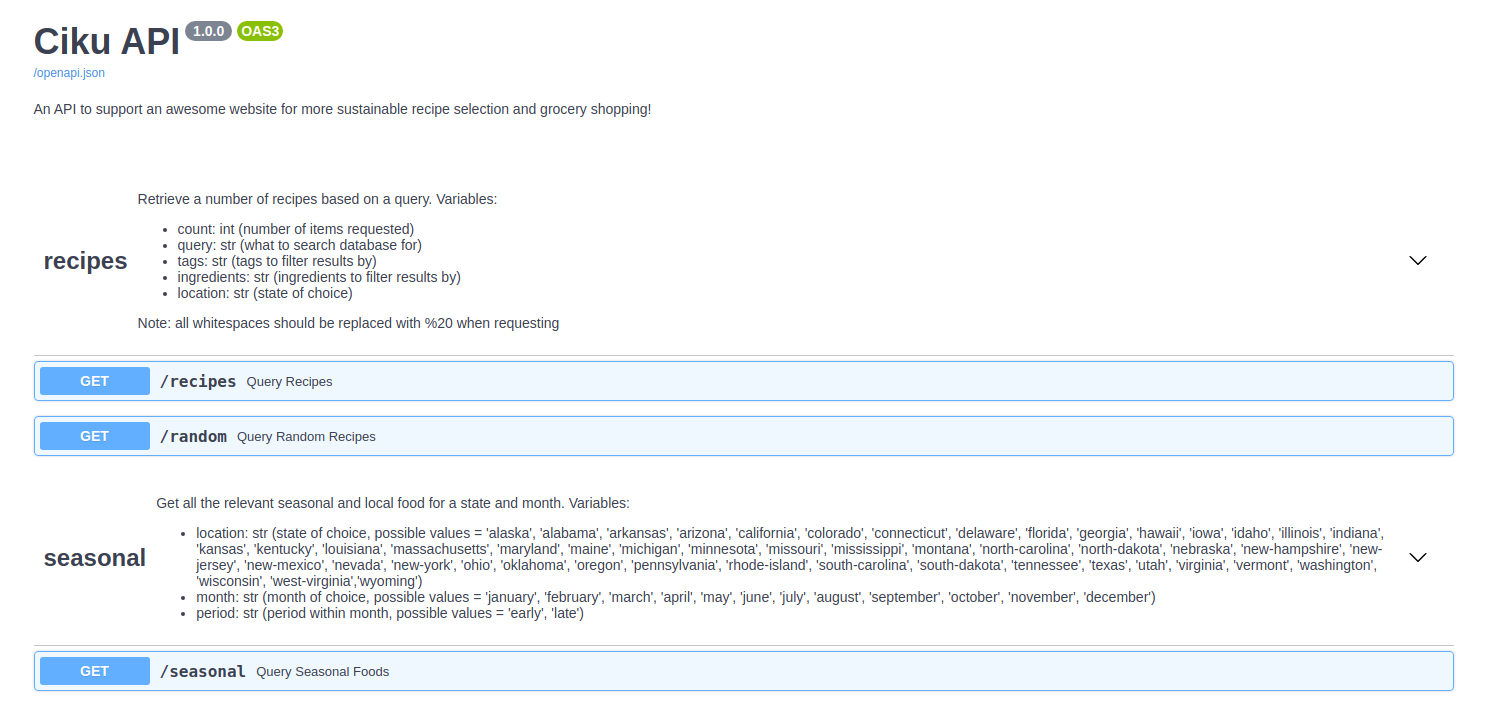
Ciku
Seasonal and Local Recipe Finder
clAIRity
Airport Navigation System for the Visually Impaired
Bot Classification
Runescape Bot Detector
GE Prediction
Runescape Grand Exchange Price Prediction
What I hope shines through all these projects is a love for applying machine learning to anything I can get my hands on; whether that means leading teams or building it myself. I thrive working on novel use cases and make sure that what I create touches the hands of real users.
Hi, I’m Chris! I'm currently a Machine Learning Engineer at Collins Aerospace (Raytheon Subsidiary). I'm also an incoming PhD Student in Human-Computer Interaction with a focus on applying natural language processing and symbolic AI to educational technologies.
Outside of work, I love eating food from a variety of cultures, reading tons of non-fiction, and getting to know new people. I enjoy talking about crime/sports documentaries, personal finance, and video/board games. I also grew up in Malaysia where my grandparents own a small fruit orchard (they grow durians!).
Propel Projects
Chronic Coder is my Youtube channel. I worked on several projects where I applied machine learning to online games (like Runescape and Neopets). People started seeing how much you could learn from applying AI/ML to these unique and challenging use cases. Hence, we started the Chronic Coder Academy to help people learn by doing similar projects!
This soon evolved into a much larger program called Propel Projects. Now, we put together multi-disciplinary teams of tech beginners to create a working prototype in 2 months. The goal is for them to learn through the application of their skills. It's always fulfilling watching students grow and learn in the process.
Collins Aerospace is one of the world's largest suppliers of aerospace and defense products. I’m an ML Engineer on the Foundational AI team. We’re focused on supporting AI/ML contracts and projects related to emerging technologies in aerospace.
I can’t share too much about the exact products we’re creating (patent pending and all that), but I’d love to talk about the problems we’re tackling and the technology behind their solutions. I’m going over quite a few here, but the other tiles in my portfolio are more focused on individual projects - promise! Some projects I'm working on:
Crowdsourced Weather
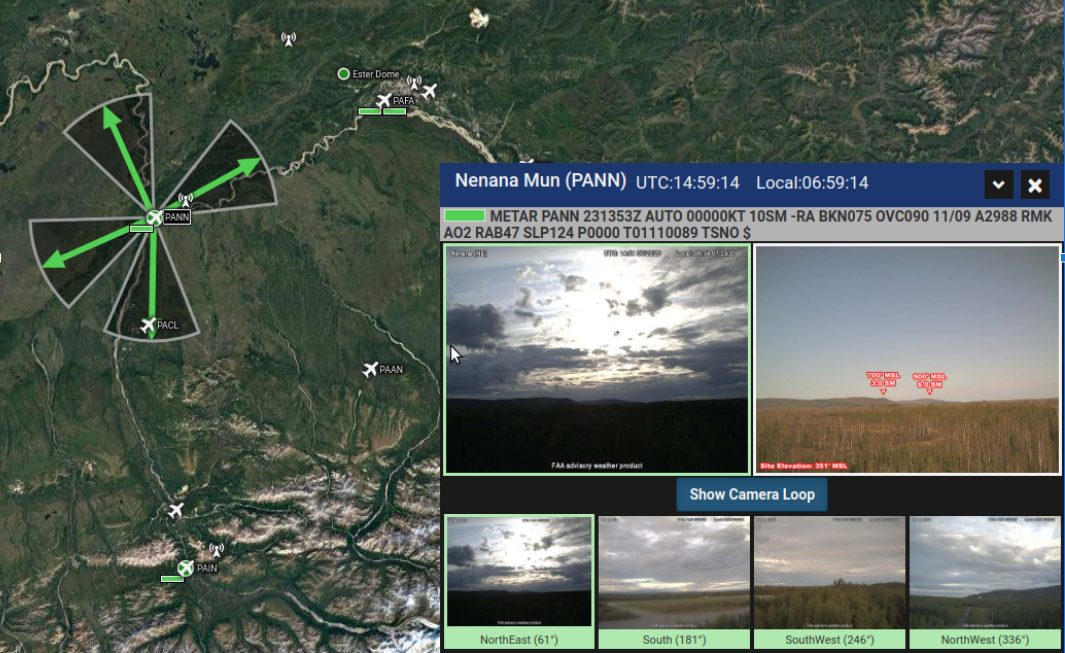
Leading a million dollar contract to develop a event-driven, cloud-based data streaming platform for crowdsourcing weather information. Processes around 10K weather camera images upon update by the FAA (typically every few minutes). The latest containerized application is built with Spark, Docker, Cassandra, S3, EC2, and Flask.
Global Weather Forecasting
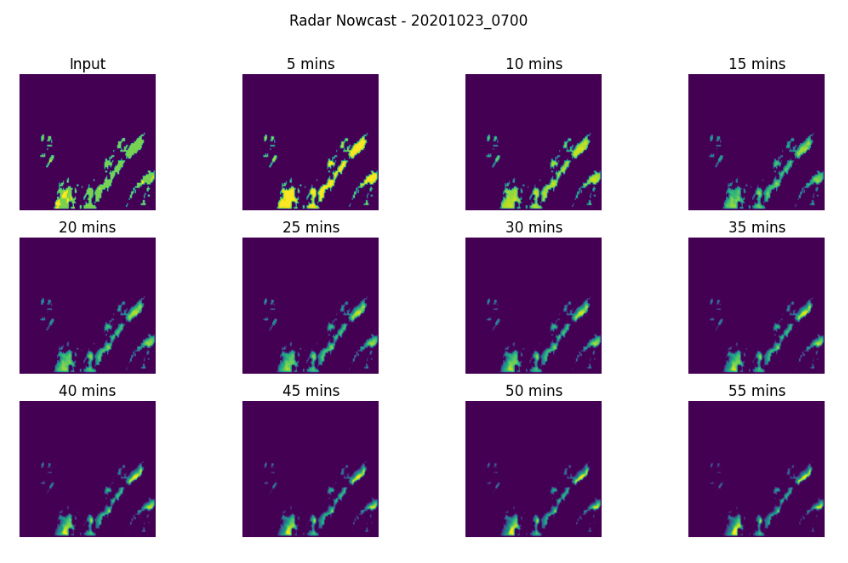
Integrating U-Net Convolutional Neural Networks with geospatial python libraries to forecast global precipitation within minutes. This process currently takes hours by the physical models being run on supercomputers.
Understanding Human Behavior
Combining few-shot meta-learning, knowledge graphs, and decision making techniques to create a holistic web-based system for understanding human actions to aid the optimization and support of airplane cabins and cockpits.
Community of Practice (CoP)
Leading the ML/AI CoP - the largest active CoP with 1000+ members and 300+ monthly attendees. Establishing connections and aligning goals of ML/AI leaders across Collins Aerospace, Raytheon, and UTC.
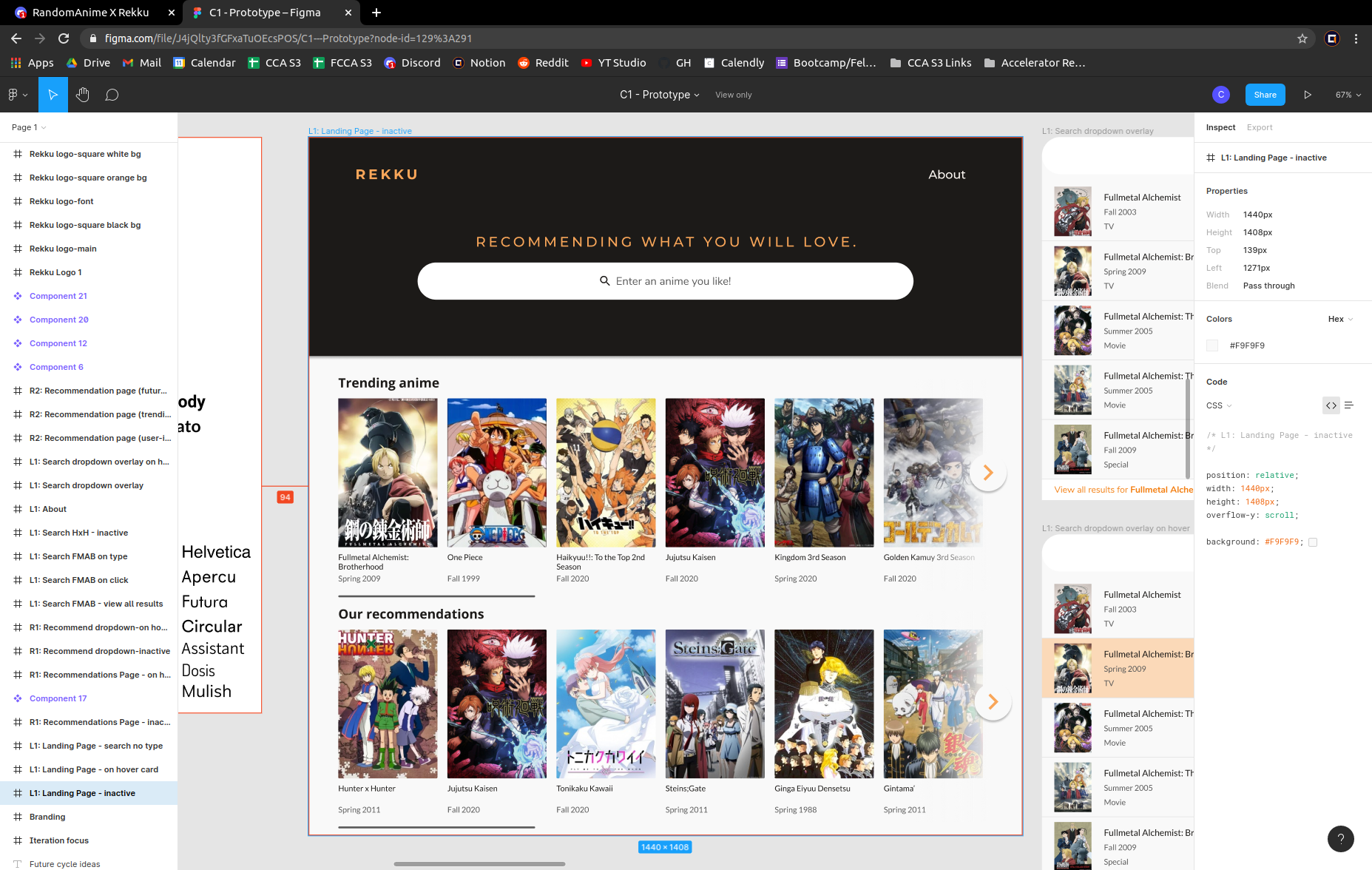
Rekku
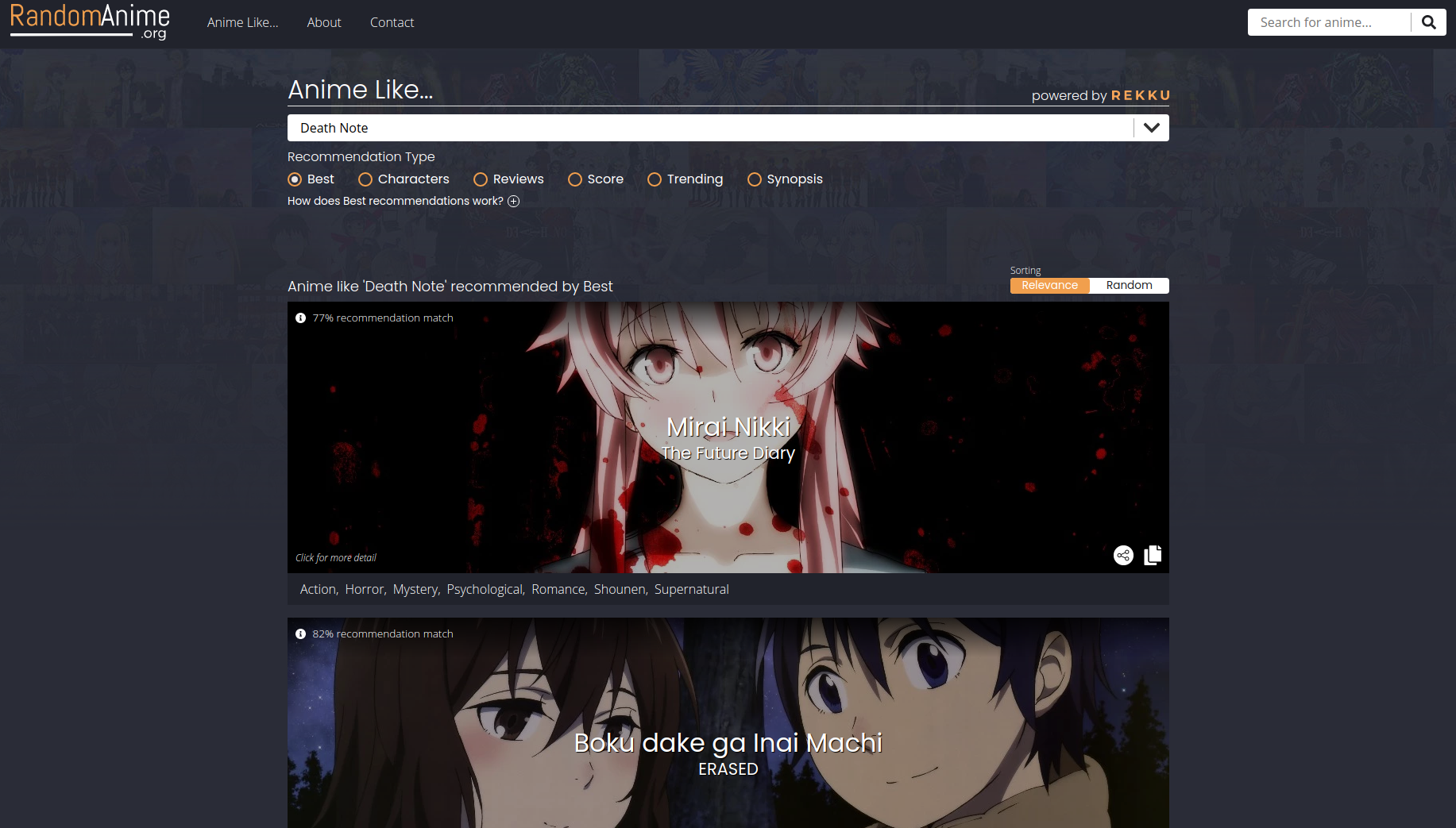
Using natural language processing and knowledge graphs to efficiently personalize anime recommendations. The Rekku API is currently deployed on a large anime recommendation website with around 80,000 unique monthly users. See it live on RandomAnime
The Problem
My friends and I were searching for some new anime to watch and realized that all of the trusted online sources were either word-of-mouth reviews or using basic filtering techniques; aside from Crunchyroll and Netflix - who only recommend their own anime. Thus, we set out on a journey to create our own system to provide personalized anime recommendations regardless of the hosting platform.
Data Collection
We started by looking for available data. There was a pretty popular anime API from MyAnimeList that we utilized at first. It provided some basic information about each anime like the genre, release date, and ratings. Through user testing, we found the need for deeper sources of data like specifics about anime characters and their tags - which we later web scraped through Anime Planet.
Data Preprocessing
We created a pipeline to collect all the new data we needed each season. The preprocessing mainly came from making sure that the anime from MAL and characters from AP matched up. There was also a lot of missing data to clean up and many outliers that were usually from different forms of anime - like Chinese webtoons or anime movies.
Data Storage
Working with a micro EC2 instance (1 GB RAM, 8 GB Memory), we really had to scale down our processing and storage to keep things running quickly. We stored everything in tables initially and later realized that the data we had made much more sense as connected graphs; between that and some data structures & algorithms magic, the API requests fell from 4 seconds to 0.1 seconds!
Machine Learning API
We tried many different algorithms and landed on a few that made the most sense to us and our user-tested audience. Some noteworthy ones include using word2vec for recommendations based on user reviews, regression based on key factors (found through user testing and validation), soft clustering based on pairs of variables.
Validation
We created a validation testing pipeline as well to make sure that the algorithms we produced were worthwhile. To judge the accuracy of the models, we used the manual user recommendations that were on MAL (we had to scrape this since it wasn’t provided with their API).
User Testing
User Testing: It has to be said that, before our integration with RandomAnime, we worked with an amazing frontend developer (Joel Wong) and an awesome UX designer (Joey Wong) to get a MVP running and demonstrable to users for usability testing. This proved to be one of the most important things for our project, getting it into the hands of users. They gave us crucial feedback which we were later able to keep reiterating on.
Deployment
As mentioned earlier, we’re using a micro AWS EC2 instance to deploy the API. We specifically set out to utilize Docker for containerization and, thus, it was pretty effortless to get up and running from there! Check out the deployed API's documentation.
Integration
After looking through the competitors, we chose RandomAnime to integrate with. The person running it seemed incredibly genuine with his love for anime (through his Instagram, Facebook, and MyAnimeList posts). Furthermore, he remained very agnostic to the hosting platforms (even going so far as to include the not-so-legal viewing options). Those viewing options were crucial for us because it was one of the most requested features during user testing and he had collected that unique dataset personally over the years.
All that said, he was also one of the largest anime recommendations on the web so it couldn’t have hurt! We had some initial talks with him while we were finalizing our API, and in about a month, our system was being used by tens of thousands of users on his anime-like page!
The Future
Now that we have live users, we’re collecting data on their preferences and what they look for in recommendations. We intend to use this data to continue improving our algorithms moving forward.
We created a platform for finding sustainable recipes that use seasonal and local produce based on your location and the time of year. Check out the Live Webapp!
The Problem
People care about seasonal and local food and know it’s important for the environment but have no idea how to find out what’s in season or local. This is especially important when deciding which recipes to follow and buy groceries for.
Data Collection
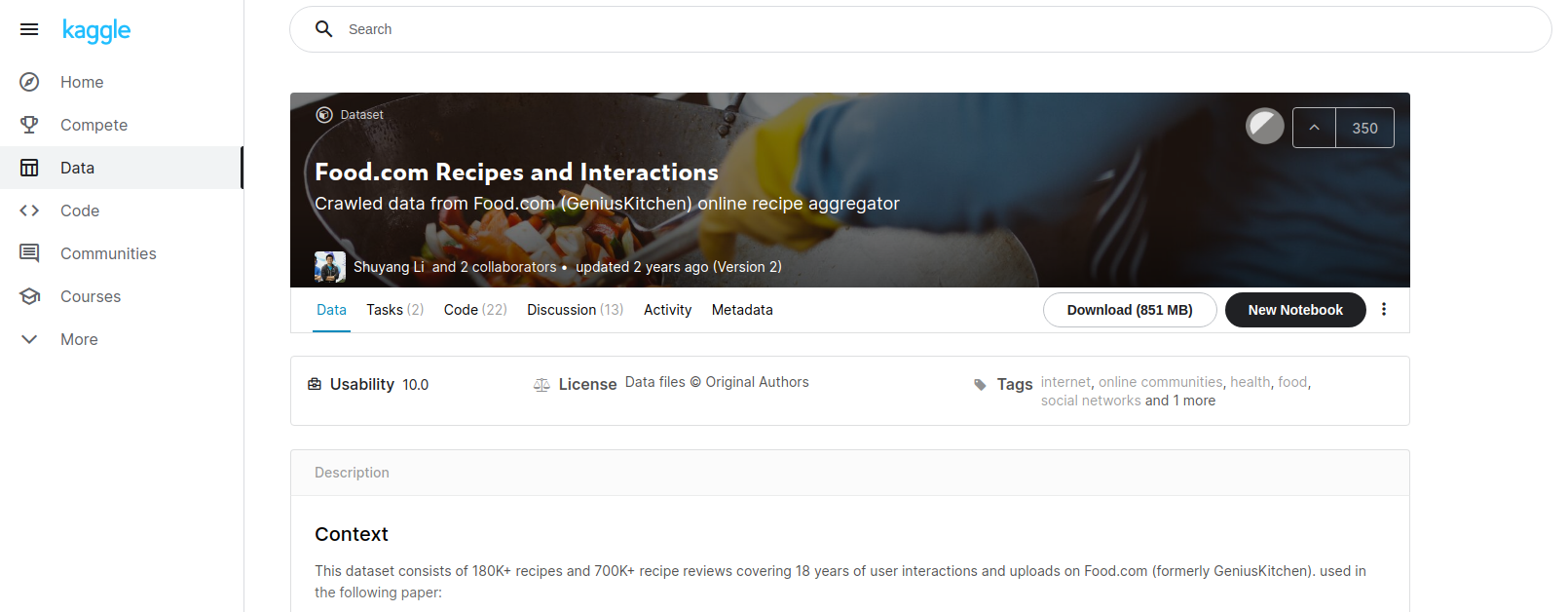
We knew off the bat that we’d have to combine several sources of data. The first was from the USDA, they have various kinds of publically available data based on the crops, livestock and other produce each year. Then, we chose to use the Kaggle Food.com recipe dataset which was scraped a couple years ago; just to get a quick set of around 200K recipes to work with. We later had to rescrape all of these (it took 6 days…) because the dataset didn’t come with images or ingredient quantities.
Data Preprocessing
The Kaggle dataset was mostly good to work with off the shelf. The only messy part was the user inputted ingredients and recipe titles where we had to apply some classic NLP autocorrection, stemming and lemmatization.
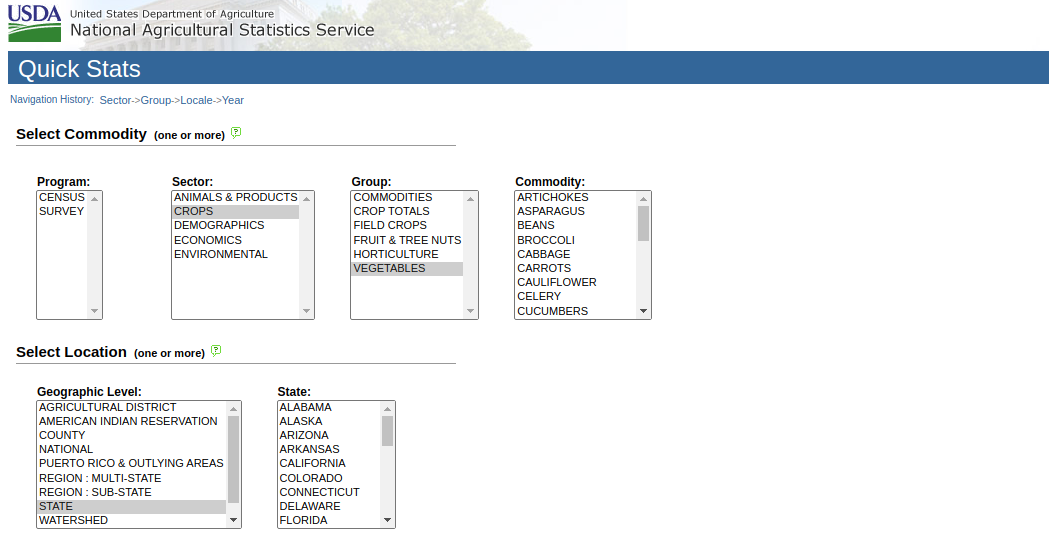
The USDA dataset, however, was a NIGHTMARE! It gets really messy here because (depending if you choose to grab the data by a specific time period or location) you could get completely different results and ranges for the output. Sure, there’d be missing produce, missing days or months, missing states to deal with but the variables, descriptions, and ways things are measured change as well based on the different selection criteria. There isn’t a large whole dataset we could pull and make sense of either, it all came in weird batches because they have limits to the amount of data you can grab at once.
Furthermore, these production values over the years are what was really important to us because to measure seasonality we chose to derive a relative ratio of production between all other months and, similarly, relative to other states for locality. Suffice to say, wrangling the data to get a simple ‘what’s in season this month at my location?’ was one of the hardest data preprocessing challenges in my life.
The API
Working closely with our awesome frontend developer, Sandy Kuo, I came up with the endpoints and parameters for the necessary app features. A lot of minor improvements showed up along the way to help efficiency, usability, and functionality; like error handling, calculating sustainability scores, or filtering. One particular challenge was matching the titles to the users query. Here, I tried a few different NLP preprocessing techniques (like stemming and lemmatization) but ended up going with partial ratio fuzzy matching which showed the quickest and most agreeable results.
Deployment
Here again, we’re using a micro AWS EC2 instance to deploy the API and Docker for containerization. Check out the Ciku API documentation!
Web Application
Again, there’s SO MUCH more happening in the background (or foreground, I guess) that went into producing the frontend and user experience surrounding Ciku. We were actually just aiming for sustainability when we started, we slowly narrowed down to this niche based on some amazing interviews conducted by Antonette Adovia. She and Sandy worked out and executed on the design that’s currently on the web app. A recent usability test showed that a lot of people love many of the app’s unique features and already want to start using it!
The Future
After usability testing, it was also clear to us what to work on next to keep upgrading our product. On my end, we’re aiming to involve more machine learning in recommending recipes to users based on the data we collect. We’re also hoping to further define and clarify the process of scoring the recipes in terms of sustainability. Other than that, we’re going to start taking in user submitted recipes and reviews which will lead to a lot of opportunity for heavier NLP usage.
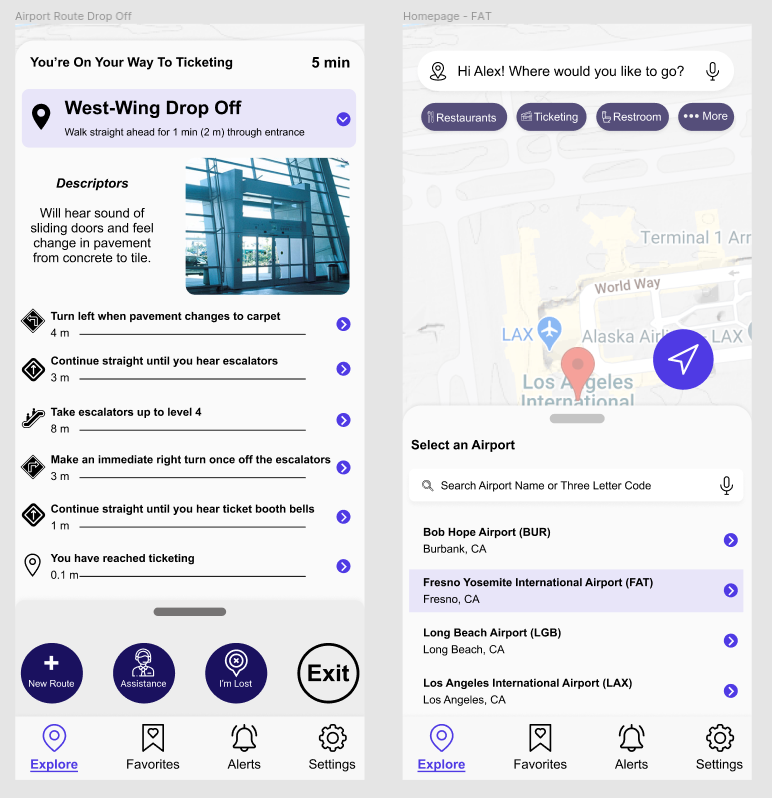
clAIRity is an app for the visually impaired (VI) that simplifies airport navigation. The app will allow the VI to get clear directions while navigating the airport using their preferential method (text input or voice commands).
This is one of the 4 Chronic Coder Academy (CCA) projects in our 3rd Cohort that I personally led. I was the project manager for the project instead of an engineering one; leading a wonderful team of 3 (Elaine Liu - Backend, Faith Chua - Frontend, Kenny Tran - UX).
The Problem
The visually impaired have trouble navigating large open spaces especially ones that are new to them. Airports are one of the biggest challenges faced and the VI would usually have to ask for assistance upon arrival.
The Methodology
For most CCA projects, I follow Basecamp’s shape-up methodology which is set up for 6 week development cycles in teams of 3. It always helps our teams clearly write out the pitch, take our bets on the right approach/ideas, and finally execute by slowly breaking things down into chunks. I’ll elaborate on how these went in the next couple sections.
The Pitch
The idea behind clAIRity first came from a want to do social good. We brainstormed a few ideas and landed upon something related to computer vision for assisting the VI (taking slight inspiration from the k-drama “Startup”). After some great initial interviews with visual impairment experts, Kenny found out that one of the biggest pain points plaguing the VI was airports (large, open, unfamiliar spaces that they’d have to use to travel).
Using this knowledge, Kenny and I drafted out the pitch for identifying the problem, the solution, the rabbit holes that might take us a while and the no-gos to avoid during this cycle. Special emphasis here would be on the solution, shape-up goes into detail about keeping it high level to allow for the autonomy of the team members working on their individual roles. Hence, the solution consisted of a summary and also some high level technical requirements and visual aids.
The Process
Once the pitch was done, it was time to start work on the project. We held weekly team meetings at the end of each week to discuss projects and next steps. I’d write down the action items for their reference and check up on their progress through text mid week. Lastly, we’d hold one on ones with each of the team members every 3 weeks or so to gauge their development, interests, and future goals.
The Future
We really made strides in the technology this first cycle (making sure we can convert maps into graphs, pathfinding, the initial UI, the fleshed out high fidelity UX prototype. What we really need to do from here, is get the application to follow VI app regulations (including text-to-speech audio descriptions for all the different features/buttons, larger text overall, etc.). Other than that, we still have a lot of work for the tech to catch up to the design, both from the frontend and backend to make it more robust and usable. For example, Implementing all of the missing pages from the design, and being able to take in more airports automatically.
Bot Classification
I went through quite the roller coaster trying to classify Old School Runescape (OSRS) players as bots or not bots. All the way from trying to collect data from a historically old MMORPG to handling over 2 million samples of data for some unsupervised clustering, it was a wild ride. Check out my full thought process and timeline as I progressed through this project in my Youtube Series.
The Problem
Bots are a huge problem in OSRS. It’s an old game with a strong player base but, due to lack of care by the developers, most of the players you see online aren’t human. These bots automatically take up resources, kill players, and steal loot - they do this so they can sell their in-game currency for real money. It’s called RWT (real world trading) and people genuinely make tons of money from it. This cycle leads to more and more bots being created.
Data Collection
This was one of my most interesting exercises in data collection. I had experience previously trying to visually gather information from OSRS but it was incredibly difficult because of shifts in game-view perspective and the lower resolution nature of the game itself. I spent a long time just trying to classify cows with YOLO and it eventually worked but I couldn’t imagine having to do that AND generalize it to players with their different outfits and body shapes.
However, by the time I wanted to start this project, I had created a little bit of a community surrounding my content. When I announced that I’d be taking on this project, a few of them suggested I look into specific botting software. I have never tried it before because I was never able to google search it (plus, yeah it was a little unethical - but I wouldn’t say I haven’t tried to find some). They gave me specific search terms and I landed upon some really interesting botting software and APIs.
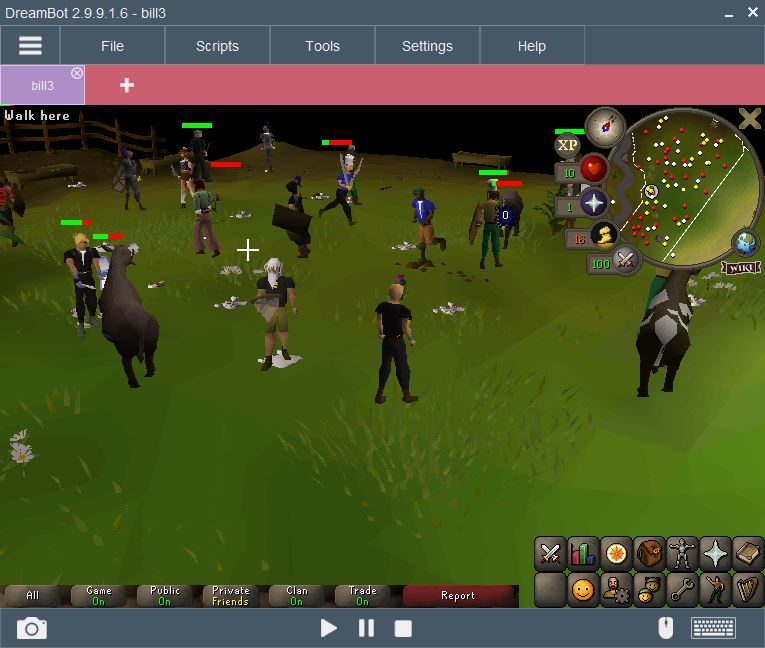
I ended up going with Dreambot, one of the more common botting software that acts as a mirror bot. It essentially mirrors your game client and uses all that information to, normally, move your character about the world for you and do things like mining, attacking others, etc. What we saw was an opportunity to use the evil software for our data collection!
The Dreambot API was entirely in Java so (after some brushing up) I started programming with that to see if I could get certain information about the players around my character. It worked like a charm! I could get data about their in-game coordinates, their movements, their skill levels, their clothes, even their animation actions.
Then, I created a server in Python that communicated with the live Dreambot Java client through SOCKETS (I swear I haven’t used this since my first year of college, who knew it’d be useful). I wanted to pipe data into Python live so that we could classify these bots on the spot when it came time - since the only way to report them typically was while they were in front of you. From there, I would let my character sit and observe everyone around it for some time before moving to another spot. Once I got a good set of data, I moved on to processing it!
Data Preprocessing
This probably took 2 or more videos to cover because we found out that there were too many ways we could try and tackle the problem. There are too many different types of bots out there with different ways of classifying them. Hence, I settled for a specific kind of bot - Suicide Bots. They usually get banned within a few days to a week because they don’t try and hide what they do. All they do is aim to get as much money as they can from one skill (e.g. Mining).
Without going too much into the gory details, here are some engineered features that worked well:
amount of skills above level 10 (to see if they were hyper focused on one skill)
mean skill level (to determine if they were dedicated to skilling to begin with)
equipment count (typically suicide bots have very minimal equipment on)
skill-of-interest minus mean skill level (again to see if Mining, Woodcutting, etc. was what they’re primarily focused on)
For the actual gory details of my exploratory data analysis, check out the Python Notebook
Data Storage
A little later on in the project, I was contacted by an amazing engineer named Dr Clint who had also been collecting this kind of data. He’s a software engineer at Amazon and was doing what I did at a MUCH HIGHER scale. He collected about 2 million samples at that point and we conglomerated the data into his DynamoDB for storage. That definitely helped the accuracy and efficiency of the model overall.
Deployment and Validation
For my final video in the series, I let my bot-detection character run for about a week. During that time, I collected data and classified them on-site. The usernames of those who were deemed to be bots were saved to a file for confirmation later on.
The validation was a little tricky for this one too because there wasn’t a clearcut way of determining if someone was banned other than checking their name on the OSRS website for skills (called hiscores). If they’re name was there previously but then taken down, we could assume they were banned.
After the week of testing, we confirmed that we had over 95% accuracy with detecting suicide bots!
The Future
These passionate OSRS folks reached out on Discord to see how they could continue development on the project. It feels amazing to have inspired such a drive for change - the future is in their hands! You can check out some of their great work and coverage here:
Everyone wishes they could automate money making. It’s no different in an online game where the power of in-game money gets you anything (even access to members-only game features). This is currently my highest starred GitHub repo and it’s been so exciting to inspire many discussions and spin-off repositories on this journey. Check out the original video series for my thoughts and progress throughout this project!
The Problem
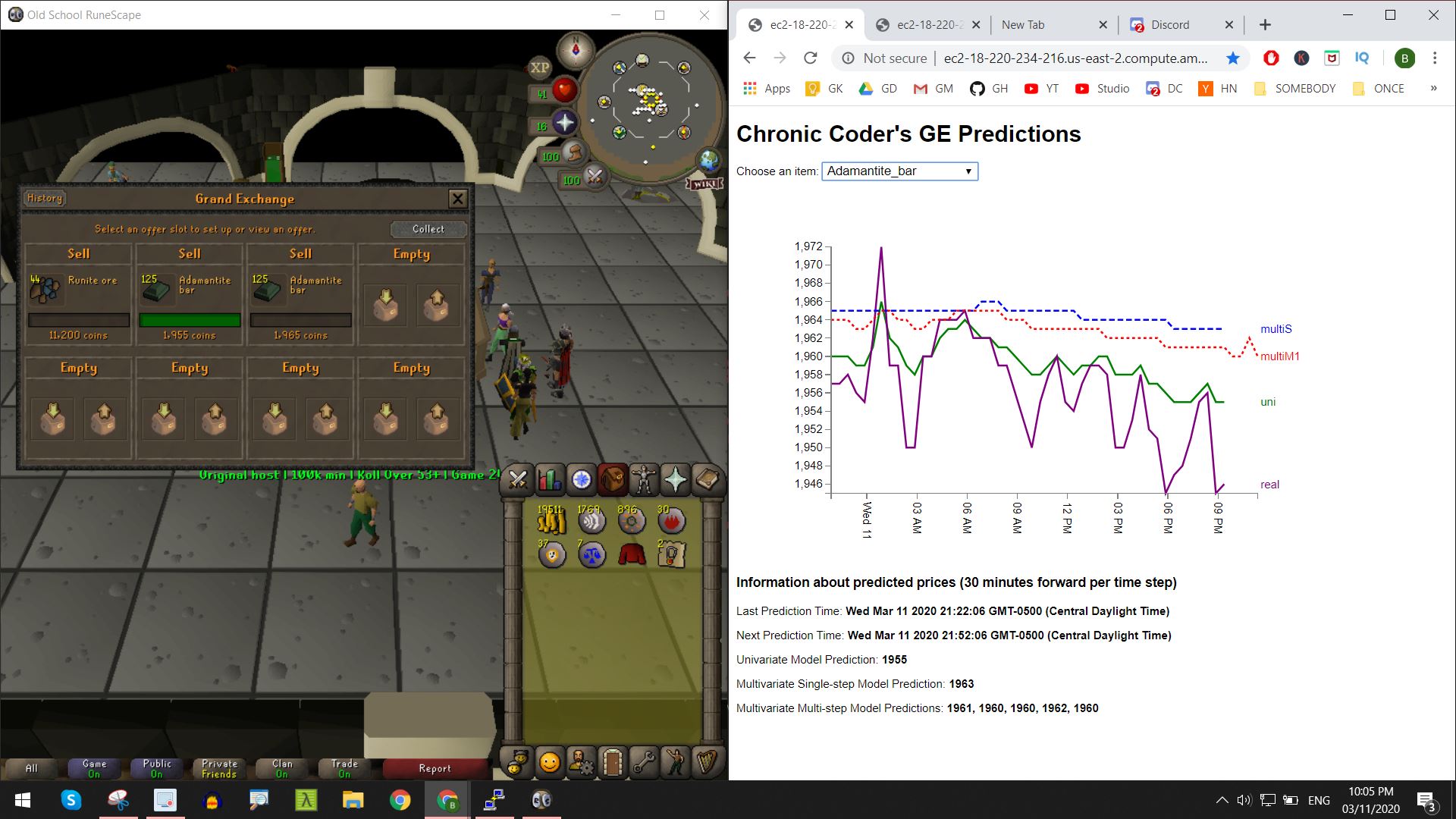
In Old School Runescape (OSRS), the Grand Exchange (abbreviated as GE) is a trading system for players to buy and sell almost all tradeable items. The price of the items are up to the game’s players. The prices fluctuate from day to day just like the real-life stock market based on demand and supply.
This leads to an amazing opportunity for money making especially for players with less time to dedicate to actually gaining resources to sell. However, just like in the real stock market, to make a profit you’d have to take some speculative bets on what will rise in price. Unlike the stock market, the price of most items don’t constantly go up due to any sort of inflation. The range of prices are pretty capped based on the trades in the past, plus none of these items will ever go away (unlike stocks that could drop out entirely).
Hence, the challenge was to use machine learning to predict item prices and come up with a strategy for optimizing our trades.
Data Collection
Thankfully, OSRS provides an API for getting data on the latest item’s prices. It’s not incredibly accurate and only updates every 2.5 minutes or so, however there have since been efforts to get more accurate and stable data by the player base. When I ran this project, they didn’t have a good source of historical data either so I had to run a cron job and save the data retrieved every few minutes. At the time, I didn’t have enough experience with EC2 or other cloud compute options so I literally left my laptop on for a week to gather the data I needed...
Data Preprocessing
This project led to some of my first standard practices in time series preprocessing. I started by dropping duplicates, filling missing values, converting datetime objects and then moving into engineered features that are used typically within time series prediction models like a moving average, RSI, differentiated signal. From there, I went through some standard feature selection procedures using recursive feature elimination, regression_f_test, etc. For a deeper dive, you can find the preprocessing code on my GitHub.
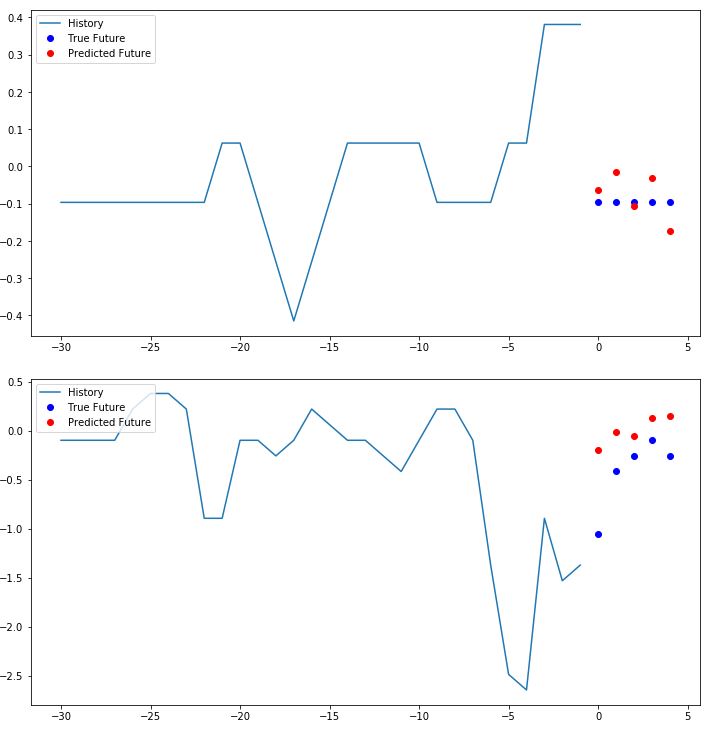
Machine Learning API
In short, I used a slew of recurrent neural networks with different settings for univariate, multivariate and multivariate multi-step approaches. I also heavily used hyperparameter tuning for the models of each individual item. Then, pairing it with the feature selection functions from the preprocessing step, we were able to achieve around 80% accuracy on average for predicting the future prices of items. For more info, check out the code.
Web Application
Our task wasn’t over yet! We needed to display the results but also use these results to inform future decisions for maximum profitability. I spun up a Flask API to grab the predicted prices for each item and displayed them on a simple bootstrapped frontend with D3.js. I also allowed users to input the amount of money they had currently and it would calculate the best set of items to buy right now if they wanted to sell in about an hour from the time of purchase to make the most profit.
At the time, it was deployed on an AWS EC2 instance but has since been taken down to make space for other projects. You can see the live project in my final video of the series.
The Future
What I’d do to improve the project was incredibly covered by a much larger Youtuber (FlippingOldSchool) who referenced my project in their video. Essentially, the prices are very reliant on the games updates and he said he’d mainly base his bets based on that along with a few other minor factors.
Other than that, I’d attempt using simpler methods for price prediction like ANOVA that have been more traditional for financial models. Finally, I would definitely incorporate Docker to pull all the pieces together.
It was an amazing journey, and although it’s no longer up I still get amazing requests for help by others taking on this same time series challenge; again it feels awesome to inspire some talented people to build fun things.